Giving AI Agents a Way to Control the Physical World
Near-infinite intelligence baked into physical products & systems is just around the corner.


In late 2024 Anthropic released the Model Context Protocol (MCP) spec, an open standard for LLMs to interact with and share data with external systems. A couple of months later a team and I spent a weekend building a robotic, AI-powered tiki bar at South Park Commons. The system talked to visitors, understood their preferences and current mood, and invented a customized drink for each of them. It then mixed up to eight ingredients in a cocktail and robotically served the beverage. Under the hood it ran surgical-grade peristaltic pumps and a sequence of servos, lights, and sensors. We won the hackathon, received an Anthropic sponsorship, and our robot got hired to mix drinks for Jensen Huang.
The interesting part is how we built it. Rather than a classical control system governed by a state machine with pre-defined drink recipes, we wanted to lean into LLM reasoning to drive the sequence. So we gave the model three things: observability into current system state (e.g. ingredient status: coconut milk → empty); control tools at the right abstraction level (e.g. dispense(2 oz, “dark rum”)); and deterministic safety and verification checks (only dispense fluid if a cup is detected, never run a pump continuously for more than 60 seconds, never dispense more than 4 oz of booze in a single drink). While frontier models have since made strides in instruction-following, we found that putting these directives in the prompt was not enough. The deterministic controls were necessary, especially for a physical system where getting it wrong isn’t an option.
Connecting models to physical systems requires:
Hardware observability = understandable system state
Semantic hardware control = bounded commands which trigger physical actions
Deterministic safety and verification layer
A system manifest providing enough context on the device and its environment
Over the last year, we’ve produced exponentially more useful agents by coupling reasoning models with CLI tools, SaaS MCPs, and other I/O. In the near future this will extend to physical products (cars, appliances) and, more importantly, physical systems (factories, farms, buildings, labs).
The following are some best practices for connecting agents to hardware, and how it can improve our built world.
The Need for Model-Native Hardware Interfaces
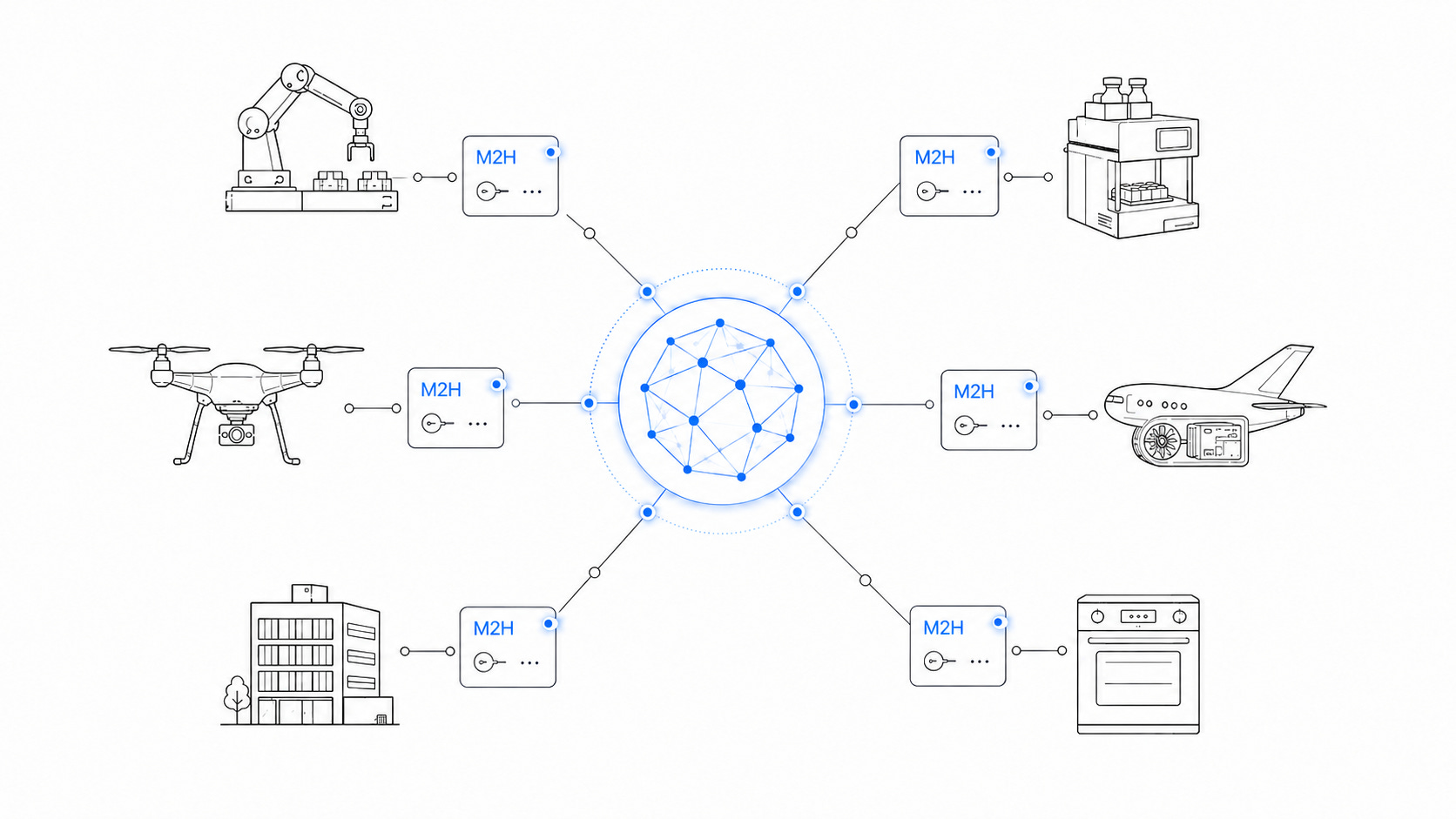
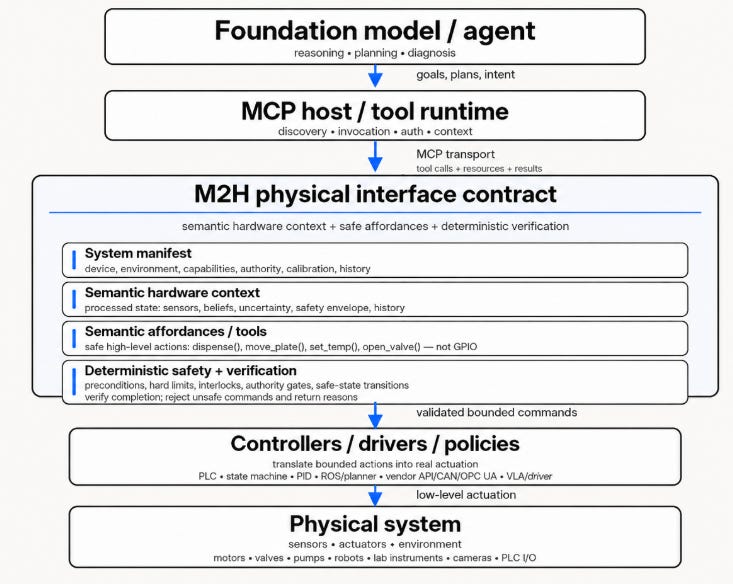
MCP gave foundation models a standard way to reach software. The same approach is what’s needed for hardware: a standard way for models to understand and act through physical devices. And like MCP, it has to operate at an abstraction level that means something to the model. For example, GitHub create_pull_request, not raw MySQL writes. A model to hardware (M2H) wrapper for physical devices should expose to the model:
Hardware context: a processed, semantic view of the device, its environment, its safety envelope, its capabilities, its uncertainty, and its history.
Hardware affordances: safe, high-level actions the model may request, which deterministic controllers (state machines, planners, PID loops, PLC logic, robot policies, lookup tables, learned action models like VLAs) translate into real actuation.
A single model-connected product is meaningfully more useful than its counterpart. Take an electric car: an interface surfaces context (state of charge, pack health, tire pressures, cabin temperature, recent drive cycles) and control commands (precondition, schedule_charge, set_target_soc, lock). The agentic model can then predictively set an optimal state of charge based on tomorrow's calendar plans, charging to 70% for a normal commute but topping up to 100% and preconditioning the battery the night before a road trip, all without the user ever opening an app.
The real leverage, though, shows up when you start composing them.
Beyond Automation: Orchestrating Device Fleets for True Autonomy
Codex running my microwave is great for cooking steamed eggs (hint: use a low duty cycle), but orchestrating every appliance in the kitchen to put out a dinner party is where the real unlock happens. Controlling one device is an automation, but a network of interrelated devices is autonomy. Here are a few examples.
Factories That Diagnose Their Own Failures
Consider a process failure on an electronics assembly line. Line yield drops from 98% to 91% over one night shift. Normally this could take a human process engineer, seeing the yield number the next morning, multiple days to investigate. But in this example the agent has interfaces on the SMT pick-and-place machines, the reflow oven, the automated optical inspection (AOI) station, the in-circuit and end-of-line (EOL) testers, the facility cameras and humidity sensors. It’s also connected to various software systems via MCP such as the manufacturing execution system (MES), which tracks every board by serial number.

The agent sees the mounting yield deviation at each cron job (within minutes) and after a threshold is met, fires off an investigation. It reads the EOL failure signatures semantically rather than as raw waveforms (return loss out of spec on the RF section, 41 of 44 failures clustered there), pulls the matching automated inspection images, and finds nothing visibly wrong with the joints. It checks the reflow oven status and finds zone 2 running 5°C cool from a drifting thermocouple, but the timing doesn’t line up with the yield cliff. Then it walks the failing serial numbers back through the MES to a single reel of moisture-sensitive chip packages and pulls the dock camera log: the reel sat un-bagged on the floor for 36 hours, past its rated floor life. The defect hypothesis is delamination during reflow, invisible to AOI, fatal to the RF section.
This could not have been determined by a single instrument. It was a system level root cause analysis that required context across several machines and sensors, and core world knowledge (e.g. IC moisture sensitivity levels and failure modes). The yield number, the test signatures, the oven, the MES genealogy, and a humidity reading on a loading dock were five separate facts in five separate systems. Now that it has a strong hypothesis, the model can command bounded remediation actions. Quarantine the suspect serials, flag the reel for bake-out, open a maintenance ticket on the zone 2 thermocouple (separate issue), and email the factory manager to suggest a floor-life alarm. Not only was the issue rapidly discovered and remediated, but the process was improved for the future.
Farms That Run as Autonomous Feedback Loops
Agriculture has already seen efficiency gains from autonomous tractors, drone-based crop scouting, and other ML tooling. But these are still mostly assist functions: they take a human task and make it faster or cheaper. A self-driving sprayer is an automation. John Deere, for example, has >1M deployed connected devices, each with an API. The larger unlock is running the entire operation in an autonomous, data-driven improvement loop, where a reasoning model orchestrates a large number of sensors and machines reading and acting in unison.

Here’s a high-level snapshot of a network of model to hardware interfaces on a farm. Sensors across the fields report soil moisture, microbial soil health, machine status (sprayer capacity, pending maintenance), and other parameters, while third-party MCPs stream weather forecasts and spot prices for inputs and crops. The model can dispatch drones for real-time visual sensing, and either the VLM or specialized classifiers flag crop stress and pests down to the individual plant. (A 5,000-acre farm can hold on the order of 750 million plants; modern vision sprayers already scan hundreds of square feet per second and trigger individual nozzles only where a weed appears.) From that stream it can make control decisions: rain is likely → delay irrigation; send a drone to inspect the anomaly in sector 12; slow the harvester where soil is saturated; order a replacement oil pump before that one fails. Safety checks bound every action: a drone may only fly preset sectors at preset altitudes and only below a wind limit, irrigation flow is capped, and so on, auto maintenance restock is subject to a budget. If the model wants to deviate outside these deterministic software locks, a request can be made for human approval. Note that the farm did not need to buy a complex, integrated system from a single vendor. They were able to safely connect each of these technologies they already have to a model instance.
Aircraft That Can Reason Across System Failures
Like the Apollo 13 crew building a CO₂ scrubber from a plastic bag and duct tape, we tend to think of humans as the debug fallback when things go wrong: human intuition for the n=1 scenario. The doctor with a gut feeling who orders the off-protocol lab (Atul Gawande, in Complications, describes a patient whose rash “seemed off,” prompting him to biopsy for a rare bacteria, instinct that proved right). Captain Sully overriding ATC’s suggestion to glide back to LaGuardia and instead putting the aircraft down on the Hudson at near-perfect attitude. These low-occurrence failures are by definition unexpected, outside the training set, and not anticipated in anyone’s design failure mode and effects analysis (DFMEA). And yet, given the right context, pre-trained foundation models are surprisingly good at this kind of debugging.
Take the Boeing 737 MAX MCAS failures of 2018–19 that killed 346 people. MCAS was a poorly designed flight-control function that could command nose-down stabilizer trim from a single, erroneous angle-of-attack (AoA) sensor. One bad sensor falsely indicated a stall, and the system pushed the nose down. The right fix here is better deterministic software.1
However, agents connected to hardware can be effective as a watchdog during irregular operations. With an agent pulling context from each sensor on the aircraft, reasoning across the whole system: one AoA sensor reads stall, the other reads a normal, non-stalled angle, the trim servo is driving nose-down, the pilots are fighting the column to pull up, and 300 kts airspeed combined with other attitude indications suggest the plane is not in a stall. Conclusion: AoA sensor 1 is likely faulty. Action: neutralize trim so pilots can take over (i.e. stop the computer intervention), and warn the crew2. Or if we are being conservative with affordances for this system debug layer, just warn the crew. Networks of model-connected hardware are very good at systems-level troubleshooting, which is exactly the regime where complex electromechanical machines like airplanes fail.
Opportunities sit in nearly every complex system that requires reasoning across many physical devices and sensors: chemical plants and refineries, smart grids, power and water-treatment plants, security and defense systems, building automation, fault recovery in complex machines. Standardized, open model/hardware interfaces let users and developers connect the constituent systems with foundation models far more easily, which is what accelerates the innovation cycle.
How to Build the Interface: Context, Control, Safety
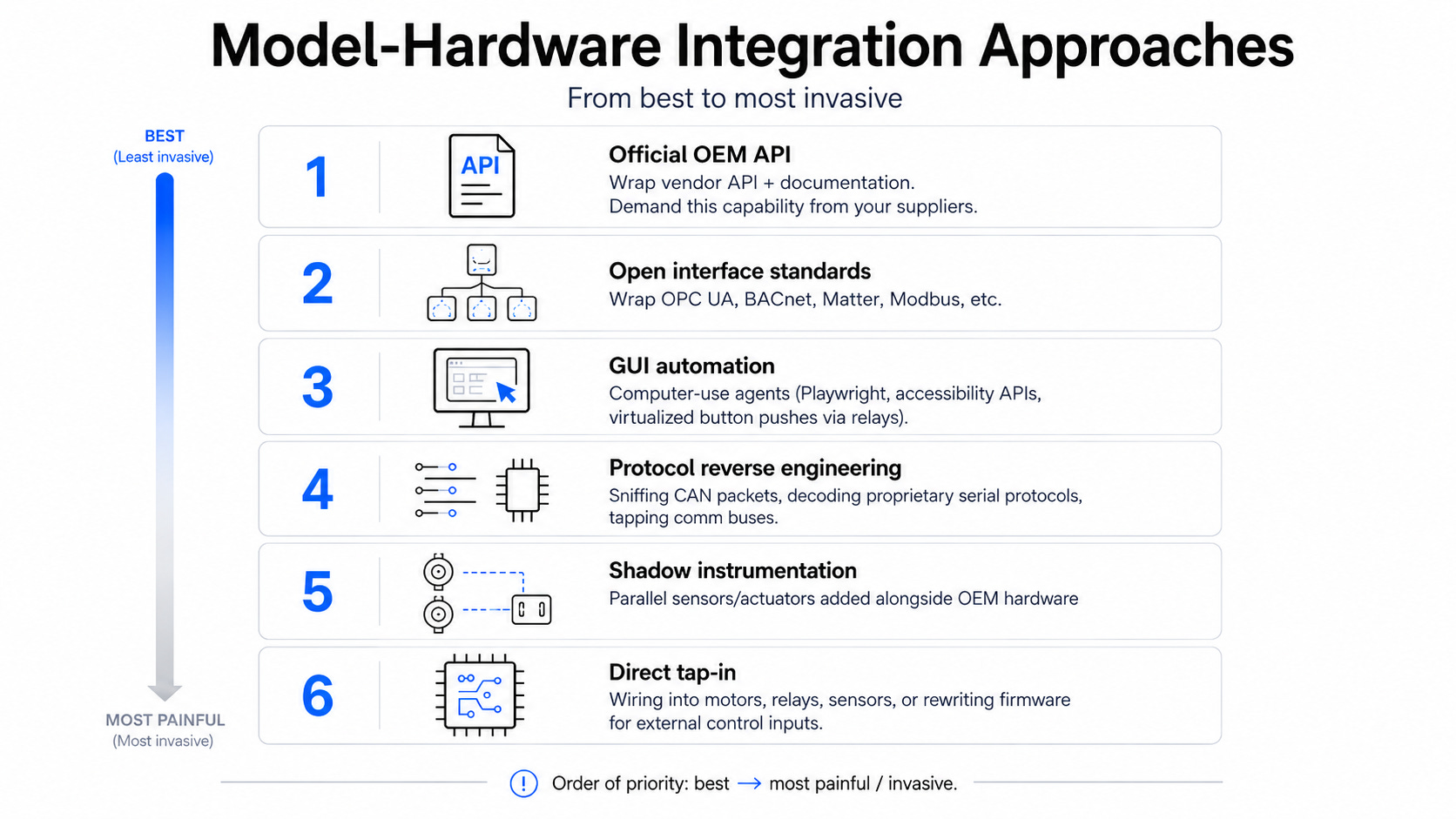
In practice, this doesn’t need to be a brand-new transport protocol. It can be profile implemented over MCP, backed by what already exists: vendor APIs, CAN, ROS, OPC UA, Matter, PLCs, and, in the unfortunate real-world case of vendor-locked walled gardens, reverse-engineered protocols and injected commands (more on that later).
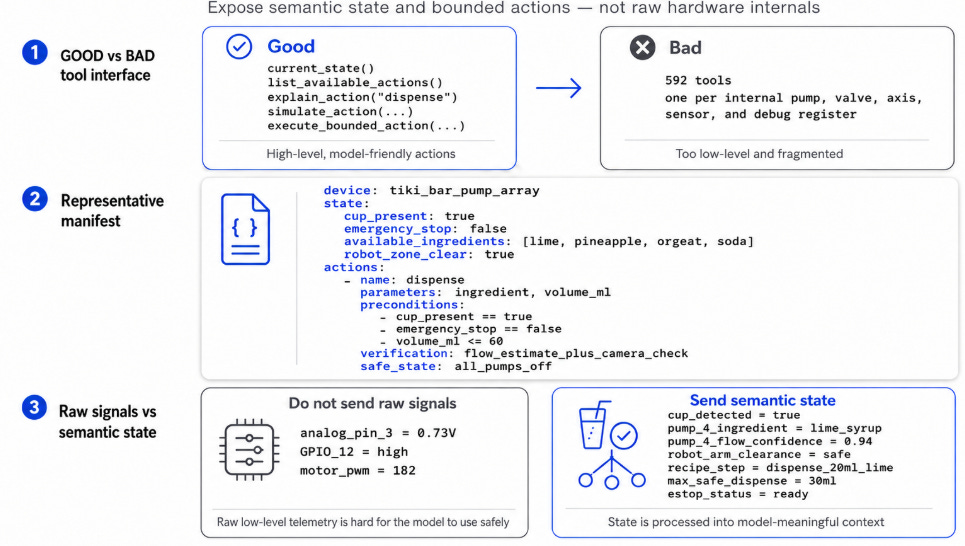
Speaking the Model’s Language: Semantic Primitives Beat Low-Level Code
For a model to talk to a physical product, it has to understand current state, and control the system in a language it understands. Models that haven’t been pre- or post-trained on a specific machine generally control it poorly at low levels of abstraction. Build a 16-DOF animatronic humanoid out of servos like I did last Halloween, hand the model a manifest of the kinematics and servo specs, and ask it to dance by emitting pwm[servo#] commands… the result is disappointing3. Give it semantic primitives like arm_up and head_turn(left) and it impresses. (Or better yet, use a VLA).
The magic is in the model’s ability to generalize. Frontier models can be fine-tuned to drive low-level sensors and actuators in a semi-continuous, token-stream, but without domain-specific post-training their ability to generalize at this level of abstraction is limited.
Hardware context is about giving the model observability into the system it’s controlling and the relevant environment. Hardware control is about giving machine-readable functions/tools/parameters to the model, and then employing specific execution algorithms to realize this command. For the tiki bar / toy example, that looked like this:
The Safety Layer: Bounding AI in the Physical World
Until we can rely on model accuracy, alignment, and cyber safety, M2H interfaces need a deterministic safety layer: hard actuator limits (max speed, force, position, duty cycle), state-machine safety (forbidden transitions, startup and shutdown procedures), precondition checks (human clear of the robot zone before motion), authority gates (when human approval is required), and verification (did the action complete).
The software interface should not trust the model to be safe. If a model asks a pump to dispense 20 ml, the model shouldn’t be the only thing deciding whether that’s okay. The verification layer checks that a cup is present, the ingredient is available, the pump is calibrated, the e-stop is clear, the volume is within limits, and the action is legal in the current state. If not, it provides feedback to the model so it understands why a command was rejected.
The same logic scales straight to lab hardware. Take a universal testing machine, an Instron load frame pulling a steel shaft to failure. The model running the experiment might ask to ramp the crosshead until the shaft shears. The deterministic layer enforces what the model can’t be trusted to enforce every time: speed below the machine’s mechanical limit, no motion while the guard is open, an absolute force ceiling below the load cell’s rating, and an immediate stop if a grip slips or force spikes faster than any real specimen could produce. The model decides what experiment to run. The deterministic supervisor decides what the actuator is physically allowed to do, since the ramifications of error are significant.
This isn’t a new lesson. MIT’s Computer Systems Engineering course (6.033) teaches the Therac-25 as the canonical cautionary tale: a radiation-therapy machine whose designers removed the independent hardware interlocks of the earlier model and trusted software to enforce safety instead. A race condition slipped through, the machine delivered massive radiation overdoses, and patients died. The lesson has held for forty years: safety-critical guarantees shouldn’t only live inside the same fallible layer that does the work. An LLM is a far less deterministic layer than the Therac-25’s software ever was, which makes its interlocks more necessary. It probably won’t always be like this, but to use a self-driving analogy we are still in the time of “safety drivers.”
At ClearMotion my team used a similar principle. A deterministic “safety supervisor” enforced hard (but dynamically calculated based on a digital twin) conditions on top of a non-deterministic reinforcement-learning controller running the car’s chassis.
With physical systems the stakes are higher and the attack surface is stranger. Simon Willison identified the “lethal trifecta” for LLM agents: access to private data, exposure to untrusted content, and the ability to communicate externally. Physical systems add input modalities humans don’t typically register as input. A label on a package, text embedded in a customer-uploaded CAD or G-code file, a sign held up to a security camera, spoofed ADS-B (aircraft identification) messages streaming into a flight system: any of these can land in the model’s context when the model is connected to the physical world. And this can be shaped to look like an instruction. The fact that the model can take physical world actions makes this vulnerability class more severe.
While the models themselves are becoming more secure against these types of attacks, the safest mitigation is the deterministic layer itself. It doesn’t trust the model’s intent, so a shaped instruction still can’t get a forbidden action past the interlocks.
When to Ditch Structured Tools: The Role of VLAs & Disposable Code
Hardware interfaces need reliable, generalizable, data-efficient, verifiable behavior, including for situations well outside the model’s training set. Compressing detailed continuous time-series state into semantic indicators, and exposing high-level control actions, lets the LLM reason at the semantic level instead of fiddling with low-level device control when semantic discretization is possible. Since most physical devices already operate through discrete states and actions (turn this on, run that centrifuge program), the model sacrifices little by honoring these abstractions.
However, in certain circumstances an unstructured approach is required.
VLAs Are Best for Continuous, Unstructured Physical Tasks
By bolting robot-action slots onto a pre-trained vision-language model (VLM) and fine-tuning it with imitation data, researchers have shown remarkable capability from vision-language-action models (VLAs) in unstructured robotic environments. Physical Intelligence’s π0, for instance, starts with a pre-trained VLM, adds the robot’s current joint state, and appends a short horizon of future action slots.
That VLAs transfer-learn from pre-trained language and vision models is genuinely fascinating, and I believe this is the future of unstructured robot control. Waymo is moving its stack toward end-to-end learning, retiring the hand-coded, layered approach that first made it the world’s safest autonomous vehicle. Tesla was an early trailblazer here and has since built a formidable data lead. But these models still need in-domain or near-domain imitation examples to be reliable: hundreds of teleoperated folding sessions, or millions of hours of driving. Even when folding generalizes to a related task like loading a dishwasher with similar arms, performance gets brittle the farther you move from the training set. VLAs are extremely useful where you need them, but unnecessary for many physical products that operate on discrete controls.
More likely is VLAs become the main control system for specific machines in a larger ecosystem. For example, a camera-equipped robotic arm might transfer specimens from one machine to another using a VLA. Such arm has a language interface with the orchestrating model.
Letting the Model Write Its Own HW Drivers (But Only After Verification)
Another option is to give the model raw access to all sensors and actuators at the lowest level and highest data rate, plus context on the system design, and ask it to write one-off code for the task. To read a button, it first writes a debounce4 routine on the right GPIO pin, then decides based on that output. This technique, for example, allows products like Claude Cowork to perform certain impressive long-form tasks that would otherwise be unreliable as a long context window model call using pre-made tools. For example, generating skills in Cowork oftentimes creates several helper functions which are better at reliability performing certain tasks than an overloaded context window.
In one sense this is exactly what model/hardware interfaces should do: domain-specific code that interprets signals and commands outputs. The difference is that you want that code fully verified and then persistent once released. Use coding agents to write it. But test and validate before release. Even a trivial debounce can hide hardware- and use-case-specific parameters a model won’t discover until real-world testing. Where the domain allows, shipping verified, audited, tested code for the context, control, and safety layers is preferable, at least at current frontier capability. Depending on your configuration, the models might be able to do this validation step itself.
Choosing a higher abstraction layer and writing validated code to bridge down to it does sacrifice some control. A model with the lowest-level access might solve a problem in an unexpected way. But the risk of hallucinated or unreliable output rarely justifies the marginal upside, especially when the abstraction is set low enough to retain flexibility. With hardware, human safety and large sums of money (sensitive lab machines, grid equipment) are on the line.
The Integration Ladder: From Clean APIs to HW Hacks
One of the key obstacles is that hardware vendors are notorious for building closed ecosystems and resisting clean APIs into their products. I saw this firsthand in the auto industry, and it has hobbled progress in fields that rely on interconnectedness, like home automation. Closed vendors want lock-in and service revenue. They don’t want liability for autonomous control, and they especially don’t want DeepMind, Anthropic, or OpenAI sitting between them and their customer (this is how the auto industry felt in the mid-2010s about Google and Apple). So the first wave of integrations will likely be user-led, arriving through adapters, wrappers, reverse-engineered drivers, user communities, integrators, gateway makers, and procurement pressure.
TLDR: Give Models Tools, Don’t Hand Them the Keys
Giving software agents tools is transforming how we process information. Giving them hardware interfaces will change how we act on the physical world. By wrapping messy physical controls in standardized, safe, model-native contracts, we trade single-purpose code for systems that can reason across any hardware they're handed. As this M2H layer matures, the payoff compounds: factories, farms, and infrastructure that diagnose their own faults, adapt to conditions in real time, and recursively optimize their own performance.
That’s a future worth building.
Alternatively, good MHP design might have pushed Boeing toward an AoA estimate produced by a Kalman filter fusing both sensors with related data into a more accurate state estimate, which on its own might have averted the failures. In the official investigation, the FAA recommended a corrective action: use both AoA sensors, add an AoA disagreement monitor, limit repeated MCAS activation, and preserve elevator authority.
Most aviation failures that lead to a loss of life involve at least 3-4 independent failures. Most complex machines have significant redundancy. Debugging root cause requires broad, live system context.
Better yet, this is a good use case for a VLA model.
Even the most trivial “hello world” designs such as a button press are complicated in the physical world. Digital designers understand that a button push can be noisy due to small mechanical inconsistencies with the switch design and ADC/digital sampler in the IC. A debounce ensures that a transient 1ms ‘off’ surrounded by 2,000 ‘on’ samples is not registered as an ‘on-off-on’ transition. Can a model be trained to understand this is a noise transient? Yes. But doing so might be wrong! If the use case is a physics experimental apparatus detecting specific types of cosmic background radiation and the transient 1 in 10,000 ‘on’ state is good signal, it would be a mistake to debounce it.