Simplify, Then Add Lightness
How to move fast when building for the physical world

When Colin Chapman said “simplify, then add lightness,” he was talking about racecars. Chapman was a legendary F1 engineer and founder of Lotus. They won races not by adding power but by removing everything that wasn’t load-bearing. He was so obsessive about weight that his engineers joked the cars were designed to fall apart the moment they crossed the finish line. Some of them did.

But the phrase means more than weight savings. It’s a design philosophy that maps onto almost every domain where complex systems must perform under constraint — which is to say, all of engineering, and most of company-building. If you’re building in robotics, aerospace, energy, defense, consumer electronics, medical devices, or automotive, this is for you.
I co-founded ClearMotion, a company developing automotive robotics that stabilize vehicle ride and handling, and we took it from a research prototype into volume production and >$100M ARR. One of the important lessons I learned is that speed in hardware development doesn’t just come from heroic effort[1]. It comes from reducing the mass of the learning loop. Delete unnecessary requirements. Collapse handoffs. Pull uncertainty inside. Push complexity from hardware into software where you can.
I made a lot of mistakes that slowed us down. Here are my top 6 hard-earned lessons about how the best teams building physical products can move fast, along with stories of other builders doing the same.
1. The fastest teams start by deleting requirements
People talk about hardware engineering as if it’s slow by nature. Build cycles. Tooling. But most of what makes it slow is managing cross-disciplinary complexity. Requirement loads, inefficient experimental design, cross-functional distance, organizational drag. Teams that succeed are usually the ones that subtract.
Earlier attempts at active suspension such as Bose’s electromagnetic system and Chapman’s own hydraulic version at Lotus aimed at very high peak force levels. On paper it’s correct when you run the math: holding a two-ton SUV flat during max cornering requires enormous static force. But that requirement pushes you toward heavy, expensive, power-hungry architectures. Bose spent decades on the problem and never shipped[2]. Chapman’s system added so much weight and complexity that it contradicted his own philosophy.
At ClearMotion, one of the most important technical choices we made was refusing to size the system for the rare, extreme on-road condition. We instrumented hundreds of cars to study actual driving profiles, not textbook edge cases, but how people actually drive and we designed around that reality. Today our fleet of customer vehicles collect data every day to better understand system usage. The result: our peak force requirement was ~20% of what others had targeted. That single subtraction opened a completely different design space. We could use a simpler architecture, which meant not just 90% lower cost but also much faster response, which resulted in better ride quality for the events customers actually experience every day. We were able to delete a number of components such as servovalves, manifolds, hoses and push most complexity into software. The tradeoff was that in a rare edge case such as aggressive track driving in an SUV, the car would revert to conventional behavior. Customers didn’t notice that, but everybody noticed the ride.
The fastest teams don’t merely optimize within the spec. They rigorously interrogate which parts of the spec aren’t absolutely necessary from a first principles perspective. A surprising amount of engineering speed can come from this.

When NASA’s Apollo program was choosing how to get to the moon, most of the agency’s leadership favored either direct ascent, landing the entire spacecraft on the moon and flying it home (the obvious approach), or Earth-orbit rendezvous, assembling a large vehicle in orbit before heading out. Both approaches required a colossal booster and extreme lunar landing capability. A relatively junior engineer named John Houbolt became convinced that lunar-orbit rendezvous, sending a small, purpose-built lander down while the command module waited in orbit, was dramatically better. He was right, but he had to go around the chain of command, writing directly to the associate administrator, to get the idea taken seriously. NASA eventually chose his approach. It was a subtraction. By removing the requirement to land the entire return vehicle on the lunar surface, they eliminated the need for a much larger booster, could use existing technologies, simplified the thermal protection problem, and made the schedule plausible. Without that architectural subtraction, Apollo almost certainly would not have made Kennedy’s deadline.
You can see the same instinct in SpaceX’s avionics. They questioned a requirement the industry had treated as obvious for decades: every critical flight computer must use space-grade components. Space radiation-hardened parts are tested to standards like less than one failure per million parts and can cost 100x to 1,000x more than commercial equivalents. Worse, they’re often a generation or two behind in performance because of the long qualification cycles. SpaceX removed the requirement at the component level and instead designed for low system failure rates through triple-redundant voting architectures, conceptually similar to how a RAID array makes unreliable disks into a reliable storage system. The result was much lower cost, faster iteration, broader part availability, and the ability to upgrade compute on a cadence closer to the commercial world. The heritage aerospace approach optimized each piece for perfection. SpaceX optimized the system for resilience and speed of development. Different spec, different design space.
For 18 years, aerospace teams tried to win the Kremer Prize for human-powered flight, most failing in the same way: they built carefully engineered aircraft around an implicit requirement no one questioned: the aircraft must not break. That requirement seemed so obvious it was invisible. But it pushed each team toward heavy, expensive designs that took months to build, and when they inevitably crashed on early flights, it took months to rebuild. Each failed attempt cost teams a year. No one could iterate fast enough to learn.

Paul MacCready, a Caltech aeronautics PhD and champion glider pilot, deleted that requirement. He didn’t build a better aircraft. He built a disposable one. The Gossamer Condor was made of Mylar film, aluminum tubing, piano wire, and tape. It weighed 55 pounds. It looked absurd. It crashed constantly. But when it crashed, his team could repair it in hours and fly again, sometimes multiple times in the same day. Over the course of development, the Condor went through more than 400 test flights and over 12 major design modifications. His competitors ran one or two experiments per year. By deleting the unexamined requirement of structural durability, he opened a completely different design space, one where the rate of learning mattered more than the quality of any single attempt. A year after starting, the Gossamer Condor completed the prize course that had defeated everyone else for nearly two decades.
The hard part is that subtraction requires courage. Often it requires a bet on the unknown. Adding requirements seems safe. But in early-stage hard tech, overdesign kills more companies than under-design. Bose’s active suspension was technically extraordinary but a commercial dead-end. Start with the right spec.
2. Good prototypes are experiments that answer the next unknown
One question I sometimes get from hard-tech founders is how we structured our milestones, and the fundraises attached to them. My general answer is: design a sequence of experiments where each one retires the next most important risk. Engage customers early but be transparent about those risks and the timeline. Find investors who buy into that journey. Sell them on the vision, customer demand, and the credible plan and progress therein. The hard part, something we got wrong on several occasions, is predicting how many iterations are needed to burn down each risk.
When developing a new hard technology, early prototypes should not be miniature production units. They should be designed the way a scientist designs an experiment: with a clear hypothesis, controlled variables, and an honest read on what the result tells you. If your prototype is trying to prove everything at once, it will likely prove nothing convincingly.
Boom Supersonic followed a disciplined sequence. Founder Blake Scholl didn’t start by trying to certify a commercial airliner, he started by asking what needed to be true first. The team built XB-1, a one-third-scale demonstrator, to retire specific technical unknowns in order: Could they design a supersonic inlet that efficiently converts kinetic energy to pressure? Could carbon-fiber composites hold up under the thermal and structural loads of sustained supersonic flight? Could a digital stability augmentation system keep the aircraft controllable at high Mach numbers without the mechanical complexity of Concorde’s control surfaces? Each flight in the test program was designed to answer the next question in the sequence — subsonic handling first, then transonic behavior, then supersonic. XB-1 broke the sound barrier in January 2025, the first independently developed civil jet to do so. Only now is Boom scaling those validated technologies into Overture, the full-size airliner.

NASA’s X-planes were the most explicit version of this idea. The X-1, X-15, and their successors were never intended as production aircraft. They were technology demonstrators, built to answer one or two specific questions: Can we break Mach 1? What happens to control surfaces at Mach 3? Can a lifting body reenter the atmosphere? and to make the answers legible enough for industry and the military to act on. The X-plane philosophy was: don’t build the thing, build the experiment that tells you whether the thing is possible.
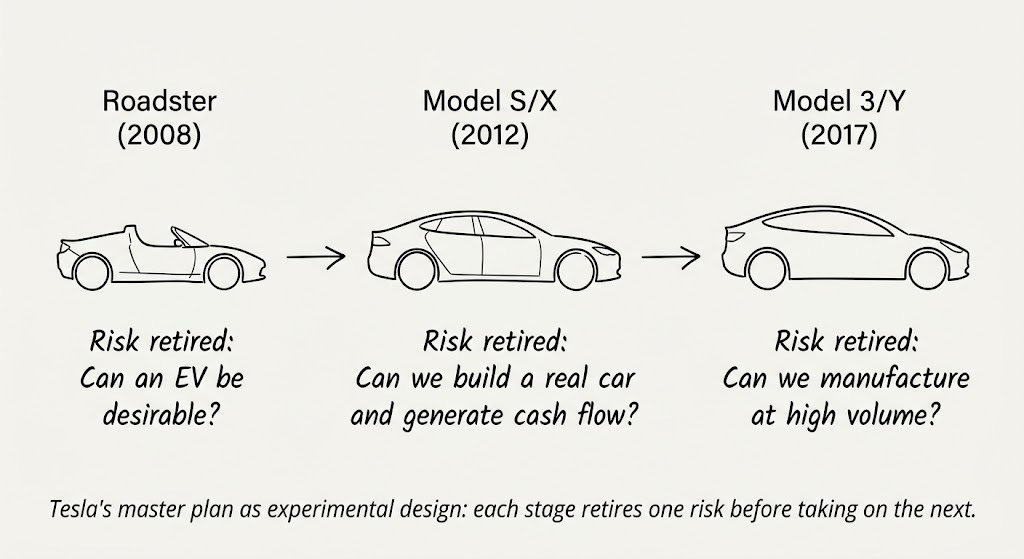
This philosophy scales to product strategy too. Tesla’s original “master plan” was deliberate. They didn’t begin by trying to build an inexpensive mass-market EV, which would have required solving cost, manufacturing scale, battery supply, brand trust, and product desirability simultaneously. Instead, the Roadster was designed to answer a narrow question: can a battery-powered car based on laptop cells be genuinely desirable? Roadster was essentially a fast electric go-kart in a Lotus Elise shell. The Model S/X tested whether Tesla could manufacture a “real” car, and generate positive cash flow doing so. Only then did they attempt the Model 3/Y, where the remaining big risk was high-volume manufacturing. Even that single risk nearly destroyed the company between 2017 and 2019. But by then they could focus on that one main thing. And they did. Two years later, they were worth a trillion dollars. The brilliance was not moving downmarket. It was sequencing the risks so that at each stage, they were burning down one main risk.
For startups, the scarce resource is usually money, but it can also be time — and time is the one you can’t raise more of. MIT spinout Lilliputian Systems raised $140 million to develop butane-powered fuel cells as portable chargers for phones and laptops. When they started in 2001, the incumbent technology was NiCad and NiMH batteries, and their energy density advantage was meaningful (five to ten times more energy per volume than lithium-ion). But they tried to solve everything in parallel: a novel MEMS fuel cell fabrication process, thermal management of a membrane that cracked under its own expansion stress, butane cartridge design, DOT regulatory approval to carry fuel on aircraft, consumer product design, and retail distribution. Nothing was sequenced. Nothing shipped. They operated largely in secret for years, repeatedly promising a product “next year.” It took them over a decade to reach a shippable product, by which point lithium-ion batteries had improved so dramatically, and dropped so far in price, that the value proposition had evaporated beneath them. They went bankrupt in 2014. The market doesn’t wait for you to finish, and the surest way to run out of time is to try to retire every risk at once.
One thing that’s changed since the X-plane era is how cheaply you can run experiments before committing to hardware. Modern simulation tools like high-fidelity CFD, FEA, multiphysics solvers have always helped here, but high performance cloud compute and AI is compressing the loop further. Surrogate models trained on simulation data can explore a design space orders of magnitude faster than the underlying solver, letting engineers screen thousands of candidates before building one. Physics-informed neural networks can interpolate between sparse test data points in ways that traditional curve-fitting can’t. None of this completely replaces physical testing, but it moves the first filter earlier, can optimize design parameters, and makes each physical prototype more informed.
The best technical teams planning the early innings of a hard-tech company internalize this. They ask: what is the next thing we don’t know, and what is the cheapest honest simulation or test that would change our beliefs?
3. Outsource the mature, insource the uncertain
A mistake we made at ClearMotion was believing we could outsource manufacturing to established system integrators before we truly understood our own process. On one hand, this appealed to our OEM customers who wanted to see a Tier-1 supplier’s name on the manufacturing line. We wanted the support of companies that “had done it before.” But on the other hand, there was an enormous amount we didn’t yet know about our assembly process and how to ensure quality at each step. When that learning happens through a supplier’s bureaucracy, then the loop slows to a crawl.
Luckily, we had the resources to learn this lesson and adapt. We built our first production line on the other side of a glass wall from where our engineers sat. Today ClearMotion owns final manufacturing for our customers, and now that there is a controlled, well-understood process, outsourcing system assembly is feasible as new factories are build around the world. The sequence matters: understand it first, then one can consider handing it off.
The general counterpoint principle is straightforward. If something is a commodity: well-characterized, mature, and not central to the unknowns in your system, then buying it is usually faster. Mobileye successfully outsourced production of their vision-processing chips to STMicroelectronics. There was very little innovation risk in their IC fabrication process; the innovation was in the ASIC design and the perception software running on it. That’s a clean separation, and for them enabled 70% gross margins and rapid growth with little marginal capex increase.[3] For PCBA assembly, for example, most processes are also standardized.
But if a system sits directly on top of your core uncertainties, outsourcing it is often the slowest choice you can make. More often than not, for complex hard-tech systems, final manufacturing, at least at first, should be your responsibility. This was incredibly counterintuitive to me at first, as the siren call of high operating margin, low capex production outsourcing is appealing to a software engineer accustomed to the ways of Silicon Valley. Investors loved our original “asset light” business model. The only problem, as we came to learn, was that it’s incredibly inefficient when the process is uncertain.
In complex mechatronics, early samples and process refinement for final system manufacturing is often part of the engineering process itself.
A small team led by Bill McLean at the China Lake Naval Ordnance Test Station developed what became one of the most successful air-to-air missiles ever built, the Sidewinder. They kept fabrication, testing, and design iteration tightly co-located and under their own control, deliberately avoiding the prime-contractor model. Where a traditional defense program would have engineers writing exhaustive specs, shipping them to a contractor, and waiting months for a prototype, McLean’s team could sketch an idea in the morning, machine the parts in their own shop that afternoon, and test it on the flight line immediately. There was no hierarchy between engineers and technicians — they worked side by side at the same benches and machine tools. Some of the best ideas came from the people closest to the metal. The missile’s roll-stabilization problem is a perfect example. The conventional approach was an electronic system: complex, heavy, and failure-prone. A technician named Sidney Crockett suggested a purely mechanical alternative: small notched metal wheels mounted on the tail fins that would spin in the airflow and act as passive gyroscopes, automatically correcting any roll. These “rollerons” were simpler, lighter, and more reliable than anything an electronics engineer working in isolation would have designed. That solution could only emerge in an environment where the person machining the parts had the standing and proximity to influence the design. The lesson wasn’t just about speed — it was that during the invention phase, the people shaping the design and the people fabricating it should be the same team.
4. Add lightness by replacing atoms with bits
One of the most impactful steps in modern hardware is shifting performance from physical complexity into software and computation—to make products “software defined.”
When my co-founder Shak and I started ClearMotion we had a motor sensing problem in a fluid system that several experienced suppliers concluded was unsolvable with our system architecture. One senior team member gave up and quit, writing a letter about why the problem was physically impossible to solve. A month later we had developed a hybrid solution that utilized an advanced control strategy in software, along with a low fidelity magnetic sensor. The solution was mostly computational. That experience shaped how I think about the boundary between hardware and software problems more than almost anything else. Later we would design the system around this principle of software-defined hardware, doing things such as continuous reinforcement learning to optimize our control algorithms, ML models to improve low-cost sensor signal-to-noise, controls to completely change the actuator dynamics, and launch new features. When in doubt, do it with software.
Google’s data centers offer an example of this principle at industrial scale. In 2016, DeepMind deployed a deep neural network to optimize cooling across Google’s data centers. This was achieved not by redesigning the chillers or airflow architecture, but by learning the nonlinear interactions between more than 120 physical variables (temperatures, pump speeds, valve positions, weather conditions) that human operators had been managing by hand. The system used only existing sensors. No new hardware was installed. The result was a 40% reduction in cooling energy, gains that no amount of mechanical re-engineering could achieve. By 2018 it was a fully autonomous control system making real-time adjustments to the physical plant. The lesson is the same one we learned with our sensing problem: the physics didn’t change, the intelligence applied to the physics did, and because the architecture allowed for the hardware to be controlled with software, the atoms became dramatically more efficient without anyone touching them.
After a series of road-debris strikes raised safety concerns about the Model S battery pack, Tesla pushed an over-the-air update that automatically raised the car’s ride height at highway speeds. It wasn’t a recall to install new skid plates (the obvious but expensive solution). It was a software change, deployed over the air, overnight, at zero marginal cost per vehicle and it used a digital lever to solve a physical world geometry problem. Software-defined hardware has post-sale elasticity that physical-only systems can’t match.

In 2013, NASA realized the aluminum wheels on the Mars Curiosity Rover were taking catastrophic damage from sharp Martian rocks. The mechanical design was locked in, and the hardware was tearing itself apart millions of miles away. Instead of accepting a shortened mission, JPL engineers developed a software-defined physical solution. They wrote and uploaded a new traction control algorithm that dynamically adjusted the speed of each individual wheel based on the suspension’s tilt and the terrain it was climbing. The software ensured the wheels pushed and pulled in harmony, drastically reducing the sheer physical forces driving the wheels into sharp rocks. Code effectively added a protective mechanical layer to the rover, extending its physical life by years. Many of these innovations require hardware designed with software control in mind. A combustion engine drivetrain can’t natively torque vector each wheel at high resolutions. But direct drive electric motors can.
At ClearMotion, our first instinct is usually to solve system challenges in software. Early prototypes were noisy due to fluid pressure fluctuations caused by pump geometry, but by controlling motor torque as a function of that geometry in software, we actively canceled the noise. By designing the system around software control, we could alter plant dynamics such as reflected inertia using predictive algorithms. AI-assisted control system design can tune thousands of parameters simultaneously against real-world data, finding operating points that manual calibration would take months to reach. When we needed to calculate forward road contour with high accuracy, we used existing vehicle sensor data to build high-fidelity HD maps of the road, crowdsourced them, localized cars against that data, and controlled the ride to mitigate road input based on infinite preview. We were the first to implement reinforcement learning for vehicle control outside of automated driving, using a deep learning framework that improves performance over time and adapts as the vehicle, road, and hardware components change. These software approaches allowed us to move much faster than physical redesigns.
Rich Sutton’s “Bitter Lesson” from AI research is a loose analogy here. His observation is that over the history of AI, methods that leverage computation have consistently won out over methods that leverage human-engineered domain knowledge. The temptation is always to build in more structure, more hand-crafted features, clever mechanisms. But the approaches that scale are the ones that replace bespoke complexity with general computation. I think something analogous is happening in physical systems. The teams best poised to win are the ones that replace mechanical complexity — bespoke linkages, exotic materials, additional sensors — with compute over simpler hardware. Because software is iterable. You can update a model in an afternoon. Retooling a casting takes months.
When you shift control authority into software, iteration loops are faster—whether you’re mitigating failure modes, adding functionality, or adapting performance.
5. Increase bandwidth between design, test, quality & manufacturing by decreasing distance
Taiichi Ohno, architect of the Toyota Production System, used to draw chalk circles on factory floors and make engineers stand inside them for hours, just watching. The point wasn’t discipline. It was bandwidth. An engineer standing next to the process absorbs information (e.g. vibration, timing, sources of waste) that isn’t in a written report. Toyota brought this philosophy to the United States through NUMMI, a joint venture with GM at a plant in Fremont, California.
Decades later, Tesla bought that same factory. During the Model 3 production crisis, Elon Musk was sleeping on the production line floor, working with the team to solve each #1 bottleneck. He said, “I always move my desk to wherever the biggest problem is.” Same building, same insight Ohno had codified fifty years earlier.
At ClearMotion we hired an early team of tinkers, expert engineer-builders who liked to see their creations come alive. Each office we built had a build/test lab adjacent our desks or with a glass wall where our engineers could see builds happening. We worked with several machine shops, mostly within a 2 hour drive of Cambridge, MA, but increasingly realized that even that had costs: misunderstood drawings, late deliveries, quality defects that took a week to fix, the need for a procurement team to manage suppliers, etc. As soon as our financing could support, we brought extensive machine shop capabilities in house so our design-release to parts-available loop could be same day instead of two weeks. We moved faster.
For a hard-tech founder, the reality is much simpler: when your toolmaker, process engineer, line integrator, and engineers can all physically stand around the same workbench on a Tuesday afternoon, problems that usually take multiple Zoom calls and DHL shipments are solved in hours.
This, far more than inexpensive labor, is the structural secret behind China’s manufacturing dominance. Their ultimate advantage is unparalleled density. When we built a brownfield factory outside of Shanghai we were able to source almost every component locally. Our line integrator was local. We hired experienced, hard-working staff that had launched products with these suppliers (and OEM customers) before. We accomplished in 6 months what took us 24 months in the USA (where we had to work with distributed suppliers, integrators and partners).
If you want your hardware team to move fast, you have to aggressively compress physical learning loops. Every mile of distance between engineers and the physical reality of the product (build, test, produce) is a tax on your speed.
6. Small teams are lighter teams
The final form of lightness is organizational.
Communication overhead in a team grows at roughly the square of the number of people. In hardware, where artifacts are physical, multimodal, deeply domain specific, and can’t be diff’d or version-controlled as cleanly, this becomes a major bottleneck to speed.
The legendarily fast and ambitious Lockheed Martin Skunk Works division operated on the principle: use 10-25% of the headcount that a normal program would use. The SR-71, the U-2, the F-117 were all built by teams that were tiny by aerospace standards. The Skunk Works leader Kelly Johnson had fourteen rules, and several of them were essentially about keeping the team small enough that everyone shared context by default.
We saw this at ClearMotion. We experienced a noticeable drop in productivity when we grew beyond roughly thirty people, at which point we had to introduce more silos, more division of labor, and we physically didn’t fit in one room anymore. Sharing of context became slower. This is where AI might have its most underrated impact on hardware engineering— not generating designs, but compressing the informational overhead that forces teams to get big in the first place.
Lightness is also a state of mind. The most expensive hiring mistakes we made were not just hiring the “wrong people,” it was hiring people who didn’t believe things could be done another way. Early on, we could execute an extraordinary amount of work with a tiny team moving fluidly across multiple customer programs because we didn’t know any better. We didn’t know that at a Tier-1 they’d have 50 people doing the OEM applications work we had 5 people doing. But as we hired more experienced engineering managers, several advocated for larger teams, more equipment and resources, less risk. They didn’t imagine how we could credibly do the work with less. Couple that with the fact that we had a nine-figure bank account and could accommodate these requests, and it was a recipe for overspending.
Process is useful (indeed, our larger applications teams resulted in less last-minute fire drills). But process is also mass. The right question is not whether you have process. It’s whether your process is helping the system learn faster.
Hardware speed is learning speed
The best hardware teams move fast because they reduce the mass of the learning loop. They delete requirements that don’t matter. They build prototypes that answer one question. They outsource the mature and insource the uncertain. They substitute software for avoidable physical complexity. They keep design, build, test and production close together. They keep teams small enough to share context. And increasingly, they use AI tools to keep those loops fast even as the system scales in complexity.
Simplify, then add lightness. Chapman was talking about racecars, but he was describing something more general: going fast under constraint. Every hardware company operates under constraint. The next time your hardware program feels slow, don’t ask ‘how do we go faster.’ Ask ‘what are we carrying that we don’t need.’

[1] Although heroics like same day tickets to Germany with Pelican cases full of actuators is a good way to get Star Alliance Gold
[2] We ended up acquiring them for their talented team and controls IP
[3] Mobileye is one of the greatest success stories of building an automotive tech company in terms of growth and business strategy
[4] The first prototype was reportedly built in McLean’s personal garage